Working with STUDY design
STUDY designs allow performing statistical comparisons of multiple trial and dataset subsets of a STUDY without creating and storing the STUDY more than once. All the statistical designs are contained in the STUDY structure as (STUDY.design) sub-structures.
For instance, In an oddball paradigm comprising trials time-locked to oddball, distractor, and standard stimuli, a user might want to contrast oddball and distractor responses, considered together, with responses to standard stimuli. One might also want to look for differences between responses to oddball and distractor stimuli. You may handle this by defining a single STUDY structure with multiple STUDY designs.
Table of contents
One-way STUDY design
For this tutorial, we will use the STERN STUDY (0.9 Gb). Please download the data on your computer.
Description of STERN experiment tutorial data
The classic Sternberg working memory task involves presenting a list of seven letters to memorize, presented one at a time. These letters, colored in green, are interspaced with letters to ignore, colored in red, and followed by a memory maintenance period during which the subject must maintain the list of letters to remember in memory. The maintenance period is terminated by the onset of a probe letter and the subject must respond whether the letter was in their memorized list of letters or not.
Trials contained varying numbers of ignore letters (either 1, 3, or 5), and the order of memorize and ignore letters in a given trial was randomized.
Event codes are the following:
- Memorize letters: uppercase letter, for example, B, H, W, F, etc…
- Ignore letters: lowercase ‘g’, uppercase letter, for example, gB, gH, gW, gF, etc… (g stands for green, see above explanation)
- Probe letters: lowercase ‘r’, uppercase letter, for example, rB, rH, rW, rF, etc… (r stands for red, see above explanation)
The PDF document within the zip archive contains additional details about the task.
Reviewing STUDY information
Use menu item File → Load existing study and select the stern.study file. After the STUDY is loaded in EEGLAB, select the Study → Edit study info menu item. The following interface will pop up.
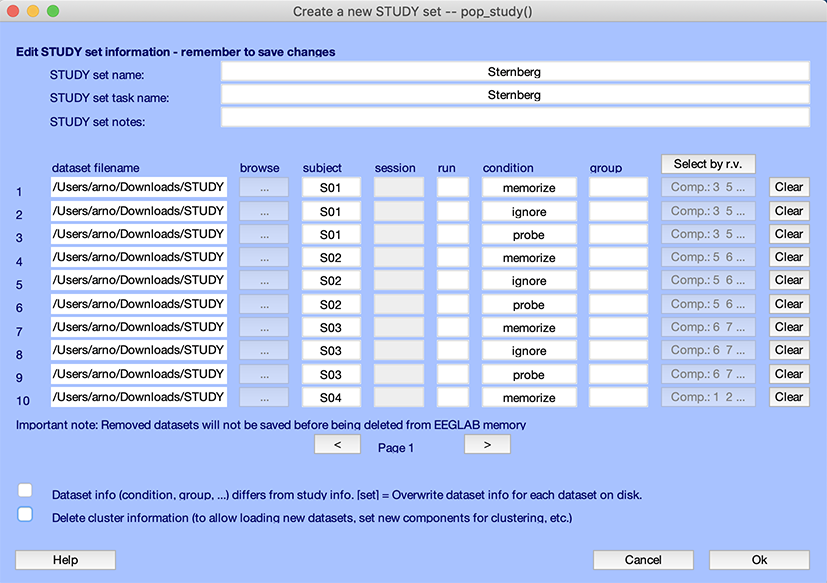
This interface contains information about the STUDY, in particular, the list of datasets, conditions, sessions, and runs associated with them. It is described in detail in the STUDY creation tutorial. In this case, it shows that for each subject, we have three epoched datasets, one containing letters to memorize, one containing letters to ignore letters data epochs, and one containing probe letters.
Looking at current STUDY design
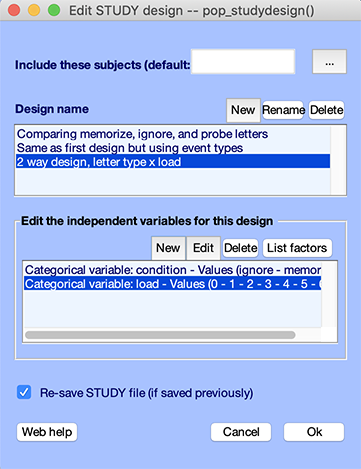
To edit the STUDY design, select the second STUDY menu item Study → Select/Edit study design(s). This will pop up the following interface.
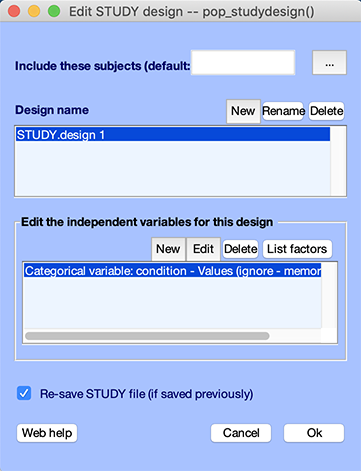
The three push buttons on the top panel may be used to:
- Add a new design (“Add design”)
- Rename a given design (“Rename design”)
- Or delete a given design (“Delete design”)
Note that the first design cannot be deleted. The design does not have a name because it was automatically generated when importing the data. You press the Rename button and name the design Comparing memorize, ignore, and probe letters.
The four push buttons on the bottom panel may be used to:
- Add a new independent variable to the current design
- Edit an independent variable
- Delete and independent variable
- List independent variables
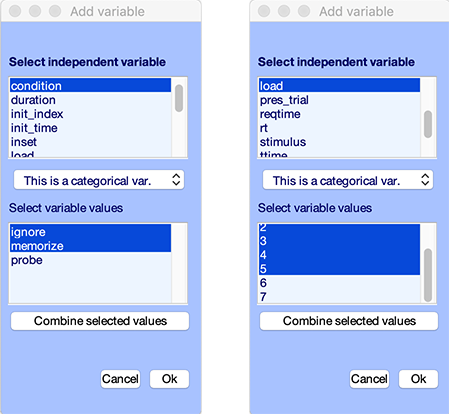
Press the Edit button in the lower panel. The following GUI pops up. We can see that the condition independent variable is selected. We can also see that the two conditions are ignore (letters), memorize (letters), and probe (letters).
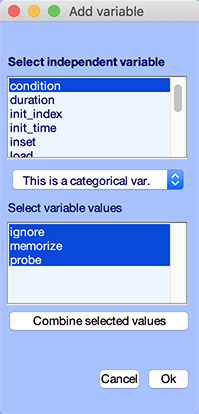
When using standard EEGLAB statistics, up to two categorical independent variables may be defined (two rows on lower panel). When using the LIMO plugin to perform statistics, an arbitrary number of continuous and categorical variables may be used.
- Categorical variables are variable that takes discrete values, such as conditions (in this case ignore vs memorize vs probe letters)
- Continuous variables are variable that takes continuous values, such as reaction time.
Once an independent variable is selected, it is possible to select only a subset of its values. All the datasets or trials not selected will simply not be included when plotting measures for that design. For instance, in this specific example, the independent variable condition may take the values ignore and memorize only to compare between the two types of letters.
Press Ok to go back to the STUDY design interface. Now press the List factor button. These are the list of independent variable values (or beta parameters) if you use a general linear model in the LIMO plugin hierarchical analysis. Refer to the LIMO plugin documentation for more information.

Creating a new STUDY design
To illustrate how to manipulate STUDY designs, we are going to create an equivalent design using event types instead of dataset conditions. Press the New design button. Then, press the Rename button and rename the new design Same as first design but using event types.
Then, select the New button in the independent variable panel (lower panel). The following window pops up. Select type for the independent variable.
- Select all the letters not preceded by g or r. These are the memorize letters. Press the combine button to combine these letters.
- Select all letters preceded by g. These are the ignore letters. Press the combine button to combine these letters.
- Select all letters preceded by r. These are the probe (recall) letters. Press the combine button to combine these letters. Go down to the bottom of the letter list and select the three sets of combined event types.
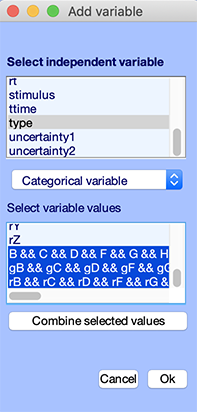
This selection is equivalent to selecting the three conditions in the previous design. However, it is conceptually quite different. In the first case, we are comparing trials contained in different datasets (i.e., EEGLAB data files). In the second case, we are only selecting event types, which may be in one dataset or several datasets.
The list of independent variables is automatically generated based on the STUDY definition information and also based on events from each of the datasets. Every single event field (as visible in the Edit → Event values) is automatically made visible. Note that only information about the time-locking event is shown, and other events within data epochs are ignored. However, EEGLAB populates empty fields within data epochs with information from other events within the same epochs. For example, events might have a field correct belonging to reaction time events (not the time-locking event) containing true or false. All events have the same fields so other events will also have a correct event field, which will be empty since it is not defined for these events. If this is the case, then the value (true or false) is automatically copied to all events within a given epoch, and may be selected as an independent variable in the GUI above. For details on what information is being extracted from datasets, refer to the STUDY design structure tutorial.
You may also read the event scripting tutorial for defining new independent variables based on event context.
Plotting ERPs for two designs
We describe in detail data plotting in the group analysis data visualization tutorial. However, we will plot and compare the ERPs for these two designs.
First, we need to precompute measures. Select menu item Study → Precompute channel measures, click the ERP checkbox, and press Ok (interface not shown). Then select menu item Study → Plot channel measures. The following interface pops up. Select electrode Oz.
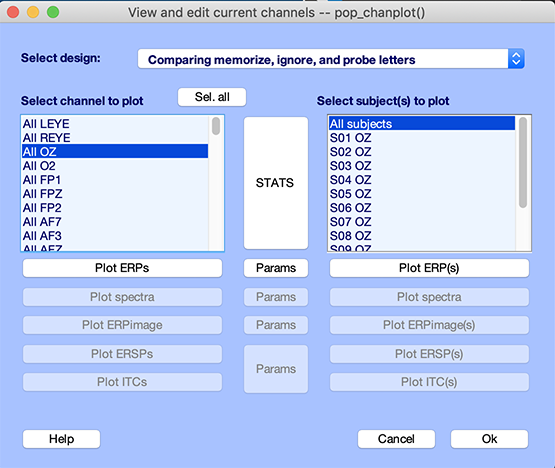
Press the Params button and select the central checkbox to plot the first independent variable on the same panel as shown below. Press Ok to come back to the STUDY plotting GUI.

Press the Plot ERPs pushbutton to plot the ERP for the first channel in the list. The following plot showing the grand-average ERP for each condition will pop up. Then in the upper part of the STUDY plotting GUI, switch to the other design and again press the Plot ERPs button. The two plots are shown below side by side.
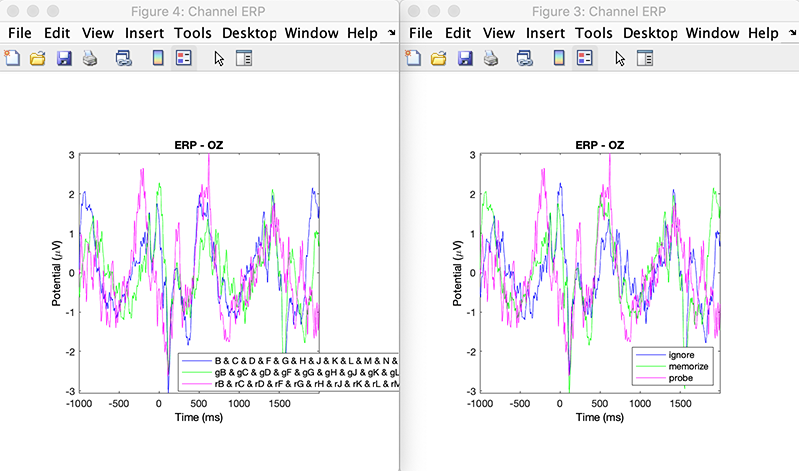
The conditions are assigned different colors, but the ERPs are identical in both conditions. This illustrates that the two designs are equivalent.
Two-way STUDY design
Each letter is preceded by other letters. Thus, when each letter is presented, there is a memory load from 0 (no other letter to remember yet) to 7. For memory load 7, there is no condition memorize (the load for the memorize letters goes from 0 to 6, which correspond to the number of letters already memorized). Note that the number of letters for condition 6 is low (a total of 31 for the ignore condition), which is why we will only select memory load from 0 to 5 below.
Again select the second STUDY menu item Study → Select/Edit study design(s). Create a third design called 2-way design, letter type x load.
For this design, use two independent variables, one is the type of letter and we select ignore and memorize (since load is irrelevant for probe letters). We also select the memory load from 0 to 5 and change the type of variable to categorical instead of continuous (it would also be possible to select continuous, but this would require using the LIMO plugin to compute statistics and plot results).
Since we have precomputed measure in the previous section, there is no need to do that again - before EEGLAB 2019, one had to recompute measures for each design, but this is no longer necessary. Select menu item Study → Plot channel measures. Select electrode Oz and press the Plot ERPs button. The following plot pops up.
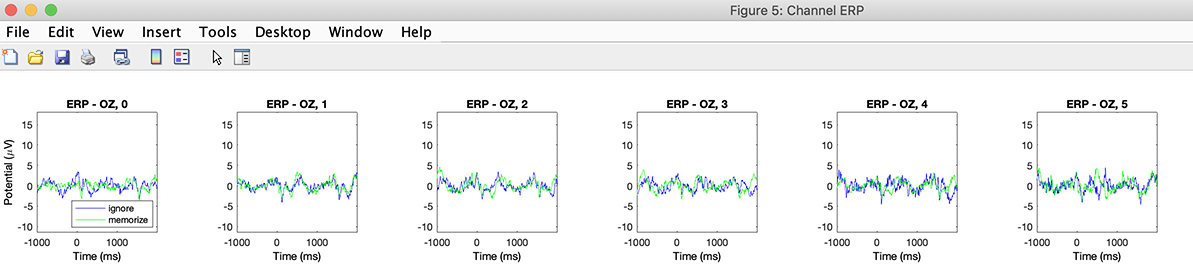
Here we have one panel per memory load. To interpret this plot, we would need to select a shorter frequency range, overlay loads for both the memorize and ignore conditions, and compute statistics. See the group analysis statistic tutorial for further details.
This simple example shows that the range of possibilities for STUDY designs is large. More details about STUDY.design structure is available in the STUDY structure part of the tutorial.
For more complex designs, one must use the LIMO EEGLAB plugin. Refer to the LIMO plugin documentation for more information.