EEGLAB Data Structures
This section is intended for users who wish to use EEGLAB and its functions in MATLAB scripts. We have tried to make EEG structures as simple and as transparent as possible so that advanced users can use them to efficiently process their data.
Table of contents
Introduction
Writing EEGLAB MATLAB scripts requires some understanding of the EEGLAB data structure (EEG) and its substructures (principally EEG.data, EEG.event, EEG.urevent, EEG.epoch, EEG.chanlocs and EEG.history). We will introduce EEGLAB data structures below.
- EEG: the current EEG dataset
- ALLEEG: array of all loaded EEG datasets
- CURRENTSET: the index of the current dataset
- LASTCOM: the last command issued from the EEGLAB menu
- ALLCOM: all the commands issued from the EEGLAB menu
- STUDY: the EEGLAB group analysis structure
- CURRENTSTUDY: 1 if EEGLAB performing group analysis, 0 otherwise
Note that EEGLAB does not use global variables (the variables above are accessible from the command line but they are not used as global variables within EEGLAB). The above variables are ordinary variables in the global MATLAB workspace. All EEGLAB functions except the main interactive window function eeglab.m (and a few other display functions) process one or more of these variables explicitly as input parameters and do not access or modify any global variable. This ensures that they have a minimum chance of producing unwanted ‘side effects’.
EEG and ALLEEG
EEGLAB variable EEG is a MATLAB structure that contains all the information about the current EEGLAB dataset. For instance, select menu item File and press sub-menu item Load existing dataset. Select the tutorial file “eeglab_data_epochs_ica.set” located in the “sample_data” folder of EEGLAB. Then press Open. Then typing >>EEG will produce the following command line output:
>> EEG
EEG =
setname: 'EEG Data epochs'
filename: 'eeglab_data_epochs_ica.set'
filepath: '/data/matlab/eeglab/sample_data/'
subject: ''
group: ''
condition: ''
session: []
comments: [9x769 character]
nbchan: 32
trials: 80
pnts: 384
srate: 128
xmin: -1
xmax: 1.9922
times: [1×384 double]
data: [32×384×80 single]
icaact: [32×384×80 single]
icawinv: [32×32 double]
icasphere: [32×32 double]
icaweights: [32×32 double]
icachansind: [1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32]
chanlocs: [1x32 struct]
urchanlocs: [1×32 struct]
chaninfo: [1×1 struct]
ref: 'common'
event: [1×157 struct]
urevent: [1×154 struct]
eventdescription: {[2×29 char] [2×63 char] [2×36 char] '' ''}
epoch: [1×80 struct]
epochdescription: {}
reject: [1×1 struct]
stats: [1×1 struct]
specdata: []
specicaact: []
splinefile: []
icasplinefile: ''
dipfit: []
history: ''
saved: 'yes'
etc: [1×1 struct]
datfile: 'eeglab_data_epochs_ica.fdt'
run: []
See the help message of the eeg_checkset.m function (which checks the consistency of EEGLAB datasets) for the meaning of all the fields.
EEGLAB variable ALLEEG is a MATLAB array that holds all the datasets in the current EEGLAB/MATLAB workspace. In fact ALLEEG is a structure array of EEG datasets (described above). If, in the current EEGLAB session you have one datasets loaded, ALLEEG will be equal to EEG. If you have two datasets loaded, typing >> ALLEEG on the MATLAB command line returns:
ALLEEG =
1x2 struct array with fields:
setname
filename
filepath
pnts
nbchan
trials
srate
xmin
xmax
data
icawinv
icasphere
icaweights
icaact
event
epoch
chanlocs
comments
averef
rt
eventdescription
epochdescription
specdata
specicaact
reject
stats
splinefile
ref
history
urevent
times
Typing >> ALLEEG(1) returns the structure of the first dataset in ALLEEG, and typing >> ALLEEG(2) returns the structure of the second dataset. See the using EEGLAB history section of the tutorial for more information on manipulating these structures. Most fields of the EEG structure contain single values (as detailed in eeg_checkset.m). However some important fields of the EEG structure contain sub-structures. We will describe briefly three of those below: EEG.chanlocs, EEG.event, and EEG.epoch.
EEG.chanlocs
This EEG-structure field stores information about the EEG channel locations and channel names. For example, loading the tutorial dataset and typing >> EEG.chanlocs returns
>> EEG.chanlocs
ans =
1x32 struct array with fields:
theta
radius
labels
sph_theta
sph_phi
sph_radius
X
Y
Z
Here, EEG.chanlocs is a structure array of length 32 (one record for each of the 32 channels in this dataset).
Typing >>EEG.chanlocs(1) returns:
>> EEG.chanlocs(1)
ans =
theta: 0
radius: 0.4600
labels: 'FPz'
sph_theta: 0
sph_phi: 7.200
sph_radius: 1
X: 0.9921
Y: 0
Z: 0.1253
These values store the channel location coordinates and label of the first channel (‘FPz’). You may use the pop_chanedit.m function or menu item Edit → Channel locations to edit or recompute the channel location information. The value of any EEG structure field may also be modified manually from the MATLAB command line. See also the tutorial section on importing channel locations.
EEG.event
The EEG structure field contains records of the experimental events that occurred while the data was being recorded, plus possible additional user-defined events. Loading the tutorial dataset and typing:
>> EEG.event
ans =
1x157 struct array with fields:
type
position
latency
urevent
epoch
In general, fields type, latency, and urevent are always present in the event structure:
- type contains the event type
- latency contains the event latency in data sample unit
- urevent contains the index of the event in the original (= ‘ur’) urevent table (see below).
Other fields like position are user defined and are specific to the experiment.
The user may also define a field called duration (recognized by EEGLAB) for defining the duration of the event (if portions of the data have been deleted, the field duration is added automatically to store the duration of the break (i.e. boundary) event).
If epochs have been extracted from the dataset, another field, epoch, is added to store the index of the data epoch(s) the event belongs to.
To learn more about the EEGLAB event structure, see the event scripting tutorial.
There is also a separate ‘ur’ (German for ‘original’) event structure, EEG.urevent, which holds all the event information that was originally loaded into the dataset plus events that were manually added by the user. When continuous data is first loaded, the content of this structure is identical to contents of the EEG.event structure (minus the urevent pointer field of EEG.event). However, as users remove events from the dataset through artifact rejection or extract epochs from the data, some of the original (ur) events continue to exist only in the urevent structure.
The urevent field in the EEG.event structure above contains the index of the same event in the EEG.urevent structure array. For example: If a portion of the data containing the second urevent were removed from a dataset during artifact rejection, the second event would not remain in the EEG.event structure – but would still remain in the EEG.urevent structure. Now, the second event left in the data might be the original third event, and so will be linked to the third EEG.urevent, i.e. checking
>> EEG.event(2).urevent
ans =
3
Event types
Event fields of the current data structure can be displayed by typing ‘’>> EEG.event ‘’ on the MATLAB command line. To display the field values for the first event, type:
>> EEG.event(1)
ans =
type: 'square'
position: 2
latency: 129.087
urevent: 1
Remember that custom event fields can be added to the event structure and will thereafter be imported with the event information whenever the dataset is loaded. Therefore, the names of some event fields may differ in different datasets. Note that event field information can be easily retrieved using commands such as >> {EEG.event.fieldname}. For example,
>> {EEG.event(1:5).type}
returns the contents of the type field for the first 5 events:
ans =
'square' 'square' 'rt' 'square' 'rt'
Use the following commands to list the different event types in the unprocessed tutorial dataset:
>> unique({EEG.event.type});
ans=
'rt' 'square'
The command above assumes that event types are recorded as strings. Use >> unique(cell2mat({EEG.event.type})); for event types stored as numbers.
You may then use the recovered event type names to extract epochs. Below is the command-line equivalent of the epoch extraction procedure presented above in section extracting data epochs.
>> EEG = pop_epoch( EEG, { 'square' }, \[-1 2\], 'epochinfo', 'yes');
Event latencies
We may use the same command as in the section above to display the contents of the event latency field. Event latencies are stored in units of data sample points relative to (1) the beginning of the continuous data matrix (EEG.data). For the tutorial dataset (before any processing), typing:
>> [EEG.event(1:5).latency]
ans =
129.0087 218.0087 267.5481 603.0087 659.9726
To see these latencies in seconds (instead of sample points above), you need first to convert this cell array to an ordinary numeric array, then subtract 1 (because the first sample point corresponds to time 0) and divide by the sampling rate. Therefore,
>> ([EEG.event(1:5).latency]-1)/EEG.srate
ans =
1.0001 1.6954 2.0824 4.7032 5.1482
For consistency, for epoched datasets, the event latencies are also encoded in sample points with respect to the beginning of the data (as if the data were continuous). Thus, after extracting epoch from the data epoch extraction tutorial, look at the first 5 event latencies:
>> {EEG.event(1:5).latency}
ans =
129 218.00 267.5394 424 513
Note that for an epoched dataset this information has no direct meaning. Instead, select menu item Edit → Event values (calling function pop_editeventvals.m) to display the latency of this event in seconds relative to the epoch time-locking event. From the command-line, you may use the function eeg_point2lat.m to convert the given latencies from data points relative to the beginning of the data to latencies in seconds relative to the epoch time-locking event. For example:
>> eeg_point2lat(cell2mat({EEG.event(1:5).latency}), cell2mat({EEG.event(1:5).epoch}), EEG.srate, [EEG.xmin EEG.xmax])
ans =
0 0.6953 1.0823 -0.6953 0
The reverse conversion can be accomplished using function eeg_lat2point.m.
The most useful function for obtaining event information from the command-line is EEGLAB function eeg_getepochevent.m. This function may be used for both continuous and epoch data to retrieve any event field for any event type. For example, using the tutorial data (after epoch extraction), type in:
>> [rt_lat all_rt_lat] = eeg_getepochevent(EEG, 'rt', [], 'latency');
to obtain the latency of events of type rt. The first output is an array containing one value per data epoch (the first event of the specified type in each data epoch). The second output is a cell array containing the field values for all the relevant events in each data epoch. Latency information is returned in milliseconds. (Note: The third input allows searching for events in a specific time window within each epoch. An empty value indicates that the whole epoch time range should be used). Similarly, to obtain the value of the event ‘position’ field for ‘square’ events in each epoch, type:
>> [rt_lat, all_rt_lat] = eeg_getepochevent(EEG, 'square', [], 'position');
Continuous data behave as a single data epoch, so type:
>> [~, all_sq_lat] = eeg_getepochevent(EEG, 'square');
to obtain the latencies of all ‘square’ events in the continuous data (via the second output).
Ur-events
A separate ‘ur’ (German for ‘original’) event structure, EEG.urevent, holds all the event information originally loaded into the dataset. If some events or data regions containing events are removed from the data, this should not affect the EEG.urevent structure. If some new events are inserted into the dataset, the urevent structure is automatically updated. This is useful to obtain information on the context of events in the original experiment. Even after extracting data epochs, the prior context of each event in a continuous or epoched dataset is still available. Currently, the EEG.urevent structure can only be examined from the command line.
The EEG.urevent structure has the same format as the EEG.event structure. The urevent field in the event structure (e.g., EEG.event(n).urevent) contains the index of the corresponding event in the urevent structure array – thereby ‘pointing’ from the event to its corresponding urevent, e.g., its ‘original event’ number in the continuous data event stream. For example, if a portion of data containing the second event is removed from a continuous dataset during artifact rejection, the second event will not remain in the EEG.event structure. It will remain, however, in the EEG.urevent structure. e.g., the second EEG.event might now point to the third EEG.urevent:
>> EEG.event(2).urevent
ans =
3
Note that urevent indices in the EEG.event structure do not have to increase linearly. For example, after epochs were extracted from the tutorial dataset,
>> {EEG.event(1:5).urevent}
ans =
[1] [2] [3] [1] [2]
This means that events 1 and 2 (in the first data epoch) and events 4 and 5 (in the second data epoch) are the same original events.
A few EEGLAB command-line functions use the urevent structure: eeg_time2prev.m, eeg_urlatency.m and eeg_context.m. The next section provides more insight into the relation between the EEG.event and EEG.urevent structures.
Event boundaries
Events of reserved type ‘boundary’ are created automatically by EEGLAB when portions of the data are rejected from continuous data or when continuous datasets are concatenated. These events indicate the latencies and (when possible) the durations of the discontinuities these operations introduce in the data. In the image below, a portion of data that included event #2 was rejected, and a type ‘boundary’ event was added to the event structure. Its index became 2, since events are sorted by their latencies. The urevent structure continues to hold the original event information, with no added ‘boundary’ event.
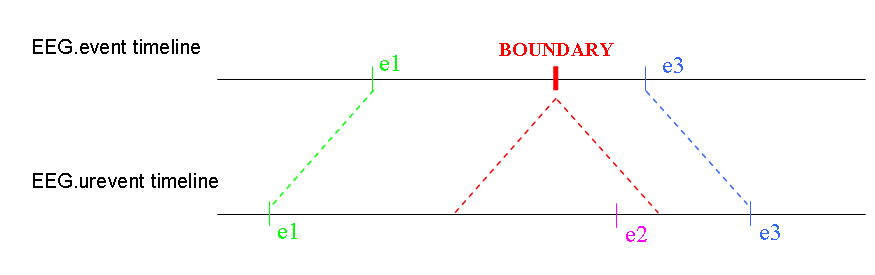
The latency of a ‘boundary’ event is usually between two samples. For example, if samples 101 to 200 are removed, then the latency of the ‘boundary’ event will be 100.5, indicating with no ambiguity that sample 101 was removed while we kept sample 100. Also, ‘boundary’ event durations indicate the number of samples removed (in the example above, 100 of them). Storing this information allows determining how much data was removed. When merging datasets, ‘boundary’ event duration is irrelevant and set to NaN.
Note that boundary events are allowed latencies outside of the data range. If the data has 1000 samples, the sample limit is 1 to 1000 (MATLAB starts at sample 1). Events at latency 0.5 and 1000.5 of type ‘boundary’ are allowed outside the data limits. These boundary events indicate that data has been removed at the onset or the end of the data, and the duration field indicates how much data was removed.
Boundary events are standard event structures with event.type = ‘boundary’. They also have an event.duration field that holds the duration of the rejected data portion (in data samples). Note that since all events in a dataset must have the same set of fields, in datasets containing boundary events, every event will have a ‘duration’ field – set by default to 0 or empty except for true boundary type events. Boundary events are used by several signal processing functions that process continuous data. For example, calculating the data spectrum in the pop_spectopo.m function operates only on continuous portions of the data (between boundary events). Also, data epoching functions will not extract epochs that contain a boundary event.
Epoched datasets do not have boundary events between data epochs. Instead of being stored in a 2-D array of size (channels, sample_points) like continuous data, epoched data is stored in a 3-D array of size (channels, sample_points, trials). Events in data epochs are stored as if the data were continuous, in effect treating the data as a 2-D array of size (channels, (sample_points*trials)). This format makes handling events from the command-line more convenient.
The purpose of the EEG.urevent structure is to retain the full record of experimental events from the original continuous data, as shown in the image below. Function eeg_context.m uses urevents information to find events defined by their neighboring event context in the experiment (and original data).
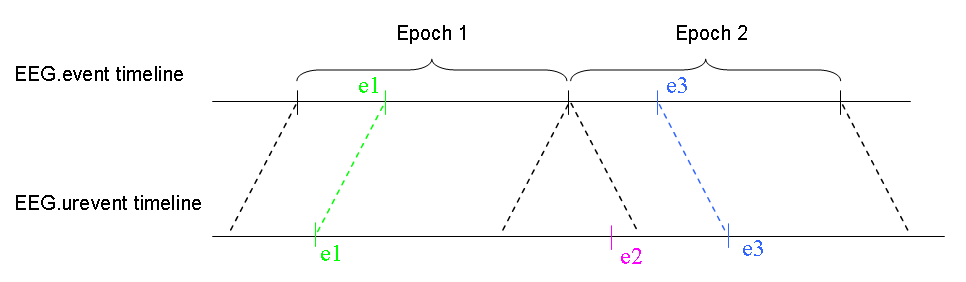
‘Hard’ boundaries between datasets. When continuous datasets are concatenated, a ‘harder’ type of boundary event must be inserted, this time into both the EEG.event and EEG.urevent structures. In particular, if the first urevent in the pair was the last event in one dataset, and the next urevent was the first event in the next concatenated dataset (which need not have been recorded at the same time), the latencies of the neighboring pair of urevents cannot be compared directly. Such so-called ‘hard’ boundary events marking the joint between concatenated datasets have the usual type ‘boundary’ but a special ‘duration’ value, NaN (MATLAB numeric value ‘not-a-number’). They are the only ‘boundary’ events present in EEG.urevent and are the only type ‘boundary’ events in EEG.event with a ‘duration’ of ‘NaN’ and an EEG.event.urevent pointer to an urevent. Hard ‘boundary’ events are important for functions such as eeg_context.m that are concerned with temporal relationships among events in the original experiment (i.e., among urevents).
EEG.epoch
The EEG.epoch structure is empty in continuous datasets but is automatically filled during epoch extraction. It is computed from the EEG.event structure by the function eeg_checkset.m (with flag ‘eventconsistency’) as a convenience for users who may want to use it in writing EEGLAB scripts. One of the few EEGLAB functions that use the EEG.epoch structure is eeg_context.m. Each EEG.epoch entry lists the type and epoch latency (in msec) of every event that occurred during the epoch. The following example was run on the tutorial set after it was converted to data epochs.
>> EEG.epoch
ans =
1x80 struct array with fields:
event
eventlatency
eventposition
eventtype
eventurevent
Note that this dataset contains 80 epochs (or trials). Now type:
>> EEG.epoch(1)
ans =
event: [1 2 3]
eventlatency: {[0] [695.3125] [1.0823e+03]}
eventposition: {[2] [2] [2]}
eventtype: {'square' 'square' 'rt'}
eventurevent: {[1] [2] [3]}
The first field EEG.epoch(1).event contains the indices of all events that occurred during this epoch. The fields EEG.epoch(1).eventtype, EEG.epoch(1).eventposition, and EEG.epoch(1).eventlatency are cell arrays containing the event field values of each of the events in that epoch. Note that the latencies in EEG.epoch(1).eventlatency are in milliseconds with respect to the epoch time-locking event.
Some datasets contain EEG.epoch.eventduration, the duration of the events in milliseconds. Note that this format is different from EEG.event.duration, which is stored as frames (but displayed in seconds or milliseconds).
When extracting epochs, it is possible to remove all but a selected set of events from the data. For example, if there is only one event in an epoch, the epoch table may look more readable. Using the tutorial dataset after extracting data epochs, select item Edit → Select epoch/event in the menu, and then enter (in the pop-up window below) ‘rt’ in the Event type field, then select Keep only selected events and remove all other events instead of Remove epochs not referenced by any event. Press Ok to create a new data set. Note: This daughter (and its future child datasets, if any) contains no trace (except in EEG.urevent) of all the events that actually occurred during the experiment but were erased by this process.
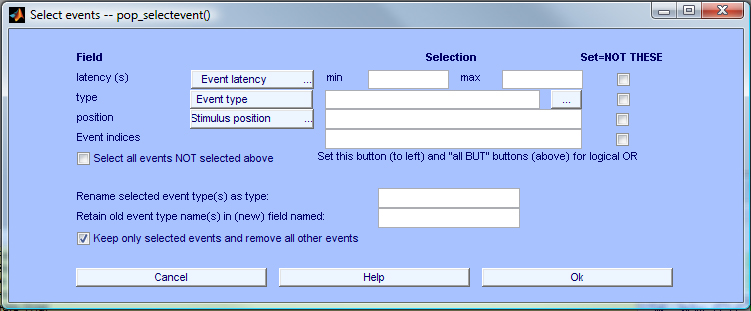
then typing
>> EEG.epoch(1)
returns
ans =
event: 1
eventlatency: 1.0823e+03
eventposition: 2
eventtype: 'rt'
eventurevent: 3
This means that epoch number 1 contains a single event of type ‘rt’ at latency 1082.3 ms. It also indicates that this is the first event in the dataset (i.e., event: 1), but note that it was the third event in the original dataset, since its corresponding urevent (stored in EEG.event.urevent) is 3.
Saved .set files
EEGLAB datasets are saved in .set files. .set files are MATLAB files. You may save an EEG structure using the command.
save -mat myfile.set EEG
This would be a valid dataset file for EEGLAB. Another supported format is to save the content of the structure itself (default as of EEGLAB 2021).
save -mat myfile.set -struct EEG
Yet another supported format is to save two files. One file that contains metadata (with extension .set, and is a type of MATLAB file), and one file containing raw data (float32 with .fdt extension). The raw data file is organized in samples x channels (so first all the data for one channel, then all the data for a second channel, etc.). In case, there are several trials, the raw data file is organized in samples x trials x channels. This is equivalent to the following MATLAB commands. Another format for the raw data file (with extension .dat) was to save the data transposed compared to the .fdt file. This format was discontinued more than a decade ago, but can still be read by EEGLAB.
data = EEG.data;
EEG.data = 'myfile.fdt';
floatwrite(data(:,:)', 'myfile.fdt');
save -mat myfile.set EEG
There are additional checks performed by the function pop_loadset.m, so it is always recommended to read EEGLAB datasets using this function.
EEG = pop_loadset('myfile.set')
The STUDY structure
This section gives details of EEGLAB structures necessary for writing custom MATLAB scripts, functions, and plugins that operate on EEGLAB STUDY structures and studysets.
The STUDY structure contains information for each of its datasets, plus additional information to allow the processing of all datasets sequentially. Below is a prototypical STUDY structure. In this tutorial, the examples shown were collected from analysis of a small sample studyset comprising ten datasets, two conditions from each of five subjects, which you may download here (1.8 GB). After loading a studyset (see previous sections, or as described below)using the function pop_loadstudy.m, typing STUDY on MATLAB command line will produce results like this:
>> STUDY
STUDY =
name: 'N400STUDY'
filename: 'N400.study'
filepath: '/eeglab/data/N400/'
datasetinfo: [1x10 struct]
session: []
subject: {1x5 cell}
group: {'old' 'young'}
condition: {'non-synonyms' 'synonyms'}
setind: [2x5 double]
cluster: [1x40 struct]
notes: ' '
task: 'Auditory task: Synonyms Vs. Non-synonyms, N400'
history: [1x4154 char]
etc: [1x1 struct]
The field STUDY.datasetinfo is an array of structures whose length is the number of datasets in the STUDY. Each structure stores information about one of the datasets, including its subject, condition, session, and group labels. It also includes a pointer to the dataset file itself (as explained below in more detail).
STUDY.datasetinfo sub-fields subject, group, session and condition label the subject, subject group, session, and condition associated with each dataset in the study. This information must be provided by the user when the STUDY structure is created. Otherwise, default values are assumed.
The STUDY.cluster field is an array of cluster structures, initialized when the STUDY is created and updated after clustering is performed (as explained below in more detail). After clustering the independent components, each of the identified components in each dataset is assigned to one component cluster (in addition to Cluster 1 that contains all components identified for clustering).
The STUDY.history field is equivalent to the history field of the EEG structure. It stores all the command line calls to the functions from the gui. For basic script writing using command history information, see the using EEGLAB history section of the tutorial.
The STUDY.etc field contains internal information that helps manage the use of the STUDY structure by the clustering functions. In particular, pre-clustering data are stored there before clustering is performed.
The STUDY.datasetinfo sub-structure
The STUDY.datasetinfo field is used for holding information on the datasets that are part of the study. Below is an example datasetinfo structure, one that holds information about the first dataset in the STUDY:
>> STUDY.datasetinfo(1)
ans =
filepath: '/eeglab/data/N400/S01/'
filename: 'syn01-S253-clean.set'
subject: 'S01'
group: 'young'
condition: 'synonyms'
session: 1
trialinfo: [1×426 struct]
comps: [3 5 6 7 8 9 11 13 14 15 16 17 19 20 21 24 25 28 29 34 35 44 52]
index: 1
This information was posted when the STUDY was created by the user.
The datasetinfo.filepath and datasetinfo.filename fields give the location of the dataset on disk.
The datasetinfo.subject field attaches a subject code to the dataset. Note: Multiple datasets from the same subject belonging to a STUDY are stored under different datasetinfo entries and are usually distinguished as being in different experimental conditions and/or as representing different experimental sessions.
The datasetinfo.group field attaches a subject group label to the dataset.
The datasetinfo.condition and datasetinfo.session fields hold dataset condition and session labels. If the condition field is empty, all datasets are assumed to represent the same condition. If the session field is empty, all datasets in the same condition are assumed to have been recorded in different sessions.
The datasetinfo.index field holds the dataset index in the ALLEEG vector of currently-loaded dataset structures. It is redundant but useful when the the substructure is used as input to another function (i.e., datasetinfo.index = 1 must correspond to ALLEEG(1), datasetinfo.index = 2 to ALLEEG(2), etc).
The datasetinfo.comps field holds indices of the components of the dataset that have been designated for clustering. When it is empty, all of its components are to be clustered.
The datasetinfo.trialinfo field holds information about each data trial. It is empty for continuous data. This field allow to create contrast between trials within a given dataset and is described below.
>> STUDY.datasetinfo(1).trialinfo(1)
ans =
struct with fields:
chan: 0
description: 'syn'
duration: 128
points: 1
type: 'S253'
The fields in the trialinfo data structure mirror the field in the event structure of the datasets (the fields are the same as in EEG.event). The field ‘type’ contains the type of stimulus. The fields ‘duration’ indicates the duration of presentation of the stimulus in samples. Other fields (‘chan’, ‘description’, ‘points’) contain information specific to a given dataset. In general, a different dataset will contain different fields.
The STUDY.design sub-structure
For the purpose of performing inference testing, any (m x n) design is possible (including choosing independent variables from among conditions, groups, sessions, particular stimulus-related trials, or other trial subsets). Below is a description of the STUDY design fields.
This is the current (v2019) STUDY.design sub-structure:
>> STUDY.design(1)
ans =
name: 'Design 1 - compare letter types'
variable: [1x2 struct]
cases: [1x1 struct]
filepath: ''
include: {}
Exploding the contents of each of these sub-structures, we obtain
name: 'Design 1 - light and audio all subjects'
variable: [1x2 struct]
label: 'condition'
pairing: 'on'
value: {'ignore' 'memorize' 'probe'}
vartype: 'categorical'
cases: [1x1 struct]
label: 'subject'
value: {'S01' 'S02' 'S03' 'S04' 'S05' 'S06' }
include: {}
-
The ‘variable’ field stands for ‘independent variable.’ Currently, up to two independent variables may be defined when using EEGLAB standard plotting functions (when using the LIMO extension to EEGLAB for calculating statistics and plotting results, an arbitrary number of independent variables may be used). STUDY.design(x).variable(1) contains the description of the first independent variable for STUDY design number x, and STUDY.design(x).variable(2) contains the description of the second independent variable (if any). Each independent variable has a ‘label’, a pairing status (‘on’, for paired data and ‘off’ for unpaired data), associated values, and a type (categorical or continuous - note that continuous variable are only relevant when using the LIMO extension to EEGLAB). For instance, in this specific example the independent variable ‘condition’ may take the values ‘ignore’, ‘memorize’ and ‘probe’. As detailed in the graphic interface STUDY.design section, values may be combined by concatenating the value labels and separating them with a ‘-‘ character. For instance ‘memorize - probe’ is a new value for the variable ‘condition’ and it points to datasets containing either the ‘memorize’ or the ‘probe’ stimuli.
-
The ‘cases’ field contains the descriptions of the single ‘cases’ (a term adopted in statistics from clinical studies). Using the current interface, it is not possible to define ‘cases’ other than subjects (although when plotting single subjects, selecting the option to use single trials for statistics automatically makes ‘cases’ equivalent to ‘trials’).
-
The ‘filepath’ field is the path where the data files are being stored.
-
The ‘include’ field is a list of independent variables and values to include in the design - for instance, to include ‘memorize’ stimuli only (and ignore all subject datasets (or, for single-trial statistics, all trials) that do not have this independent variable value.
Definition of STUDY design independent variables
Most independent variables are defined in the main STUDY interface when creating a STUDY. ‘condition’, ‘group’ and ‘session’ are independent variables defined in the first STUDY editing GUI. In addition to these variables, EEGLAB extracts independent variables for each subset of data epochs based on epoch field information for the time-locking event in each dataset. The function std_maketrialinfo.m creates the ‘trialinfo’ substructure in STUDY.datasetinfo. For instance, the first dataset in the STUDY may have the properties:
STUDY.datasetinfo(1).condition = 'a';
STUDY.datasetinfo(1).group = 'g1';
STUDY.datasetinfo(1).trialinfo(1).presentation = 'evoked';
STUDY.datasetinfo(1).trialinfo(2).presentation = 'evoked';
STUDY.datasetinfo(1).trialinfo(3).presentation = 'evoked';
STUDY.datasetinfo(1).trialinfo(4).presentation = 'spontaneous1';
STUDY.datasetinfo(1).trialinfo(5).presentation = 'spontaneous1';
STUDY.datasetinfo(1).trialinfo(6).presentation = 'spontaneous1';
STUDY.datasetinfo(1).trialinfo(7).presentation = 'spontaneous2';
STUDY.datasetinfo(1).trialinfo(8).presentation = 'spontaneous2';
STUDY.datasetinfo(1).trialinfo(9).presentation = 'spontaneous2';
The ‘trialinfo’ structure describes the property of each trial for dataset number 1. Trial number 1, 2, 3 are trials of presentation type ‘evoked’, whereas trials 4, 5, 6 are trials of presentation type ‘spontaneous1’ and trials 7, 8, 9 are trials of presentation type ‘spontaneous2’.
The function std_makedesign.m (or its GUI equivalent pop_studydesign.m) uses the information defined above to create STUDY designs. The content for the ‘variable1’ entry of the std_makedesign.m function can be either a field of ‘datasetinfo’ or a field of ‘datasetinfo.trialinfo’. Fields from ‘trialinfo’ are used in a similar way to fields of STUDY.datasetinfo structure. For instance if the STUDY.datasetinfo is defined as above.
To call std_makestudy(), simply write:
>> STUDY = std_makedesign(STUDY, ALLEEG, 1, 'variable1', 'presentation');
To select specific values for ‘presentation’
>> STUDY = std_makedesign(STUDY, ALLEEG, 1, 'variable1', 'presentation', 'values1', { 'spontaneous1' 'spontaneous2' } );
The STUDY.changrp sub-structure
The STUDY.changrp sub-structure is the equivalent of the the STUDY.cluster structure for data channels. There is usually as many element in STUDY.changrp as there are data channels. Each element of STUDY.changrp contains one data channels and regroup information for this data channel across all subjects. For instance, after precomputing channel measures, typing STUDY.changrp(1) may return
>> STUDY.changrp
ans =
1x14 struct array with fields:
name
channels
chaninds
The changrp.name field contains the name of the channel (i.e. ‘FP1’). The changrp.channels field contains the name of the channels in this group. This is because a group may contain several channels (for instance for computing measures like ERP across a group of channels, or for instance for computing the RMS across all data channels; note that these features are not yet completely supported in the GUI).
The STUDY.cluster sub-structure
The STUDY.cluster sub-structure stores information about the clustering methods applied to the STUDY and the results of clustering. Components identified for clustering in each STUDY dataset are each assigned to one of the several resulting component clusters. Hopefully, different clusters may have spatially and/or functionally distinct origins and dynamics in the recorded data. For instance, one component cluster may account for eye blinks, another for eye movements, a third for central posterior alpha band activities, etc. Each of the clusters is stored in a separate STUDY.cluster field, namely, STUDY.cluster(2), STUDY.cluster(3), etc…
The first cluster, STUDY.cluster(1) , is composed of all components from all datasets that were identified for clustering. It was created when the STUDY was created and is not a result of clustering; it is the ParentCluster. This cluster does not contain those components whose equivalent dipole model exhibit a high percent variance from the component’s scalp map. These components have been excluded from clustering (see component clustering tutorial for more information on how to exclude components from clustering). Typing STUDY.cluster at the MATLAB command line returns
>> STUDY.cluster
ans =
1x23 struct array with fields:
name [string]
parent [integer]
child [cell]
comps [array]
sets [array]
algorithm [cell]
preclust [struct]
topo [2-D array]
topox [array]
topoy [array]
topoall [cell]
topopol [array]
dipole [struct]
All this information (including the clustering results) may be accessed from the MATLAB command line, or by using the interactive function pop_clustedit.m.
EEGLAB version 14 use to contain more information pertaining to each cluster (such as the ERP, Spectrum and time-frequency data for a given cluster) and this information would be made available in this structure when a given cluster was plotted. These arrays were accessible to users but were mostly cached values used for plotting purposes (so EEGLAB would not have to reload them every time they were being plotted).
EEGLAB 2019 and later versions have adopted a simpler cache approach where all the plotted data is stored in the STUDY.cache structure. If the data is available in the STUDY cache, then the cached values are automatically returned. To access this information, it is now recommended to use the return values of the plotting functions std_erpplot, std_specplot, and std_erspplot - if necessary disabling plotting.
The cluster.name sub-field of each cluster is initialized according to the cluster number, e.g. its index in the cluster array (for example: ‘cls 2’, ‘cls 3’, etc.). These cluster names may be changed to any (e.g., more meaningful) names by the user via the command line or viathe pop_clustedit.m interface.
The cluster.comps and cluster.sets fields describe which components belong to the current cluster: cluster.comps holds the component indices and cluster.sets the indices of their respective datasets. Note also that several datasets may use the same component weights and scalp maps – for instance two datasets containing data from different experimental conditions for the same subject and collected in the same session, therefore using the same ICA decomposition and the same component indices. As described further in a later section, cluster.sets may contain several rows, each row containing a different dataset index.
The cluster.preclust sub-field is a sub-structure holding pre-clustering information for the component contained in the cluster. This sub-structure includes the pre-clustering method(s), their respective parameters, and the resulting pre-clustering PCA data matrices (for example, mean component ERPs, ERSPs, and/or ITCs in each condition). Additional information about the preclust sub-structure is given in the following section in which its use in further (hierarchic) sub-clustering is explained.
The cluster.centroid field holds the cluster measure centroids for each measure used to cluster the components (e.g., the mean or centroid of the cluster component ERSPs, ERPs, ITCs, power spectra, etc. for each STUDY condition), plus measures not employed in clustering but available for plotting in the interactive cluster visualization and editing function, pop_clustedit.m.
The cluster.algorithm sub-field holds the clustering algorithm chosen (for example kmeans) and the input parameters that were used in clustering the pre-clustering data.
The cluster.parent and cluster.child sub-fields are used in hierarchical clustering (see component clustering section of the tutorial).
The cluster.child sub-field contains indices of any clusters that were created by clustering on components from this cluster (possibly, together with additional cluster components). The cluster.parent field contains the index of the parent cluster.
The cluster.topo field contains the average topography of a component cluster. Its size is 67x67 and the coordinate of the pixels are given by cluster.topox and cluster.topoy (both of them of size [1x67]). This contains the interpolated activity on the scalp so different subjects having scanned electrode positions may be visualized on the same topographic plot. The cluster.topoall cell array contains one element for each component and condition. The cluster.topopol is an array of -1s and 1s indicating the polarity for each component. Component polarities are not fixed, in the sense that inverting both one component activity and its scalp map does not modify the back-projection of the component to the data channels). The true scalp polarity is taken into account when displaying component ERPs.
Finally, the cluster.dipole structure contains the centroid equivalent dipole location of the component cluster. This structure is the same as for a single component dipole (see the ICA sources section of the tutorial).
Suppose that Cluster 2 (artifacts) comprises 15 components from four of the datasets. The cluster structure will have the following values:
>> STUDY.cluster(2)
ans =
name: 'artifacts'
parent: {'ParentCluster 1'}
child: {'muscle 4' 'eye 5' 'heart 6'}
comps: [6 10 15 23 1 5 20 4 8 11 17 25 3 4 12]
sets: [1 1 1 1 2 2 2 3 3 3 3 3 4 4 4]
algorithm: {'Kmeans' [2]}
preclust: [1x1 struct]
This structure field information says that this cluster has no other parent cluster than the ParentCluster (as always, Cluster 1), but has three child clusters (Clusters 4, 5, and 6). It was created by the ‘Kmeans’ algorithm and the requested number of clusters was ‘2’. Note that as of EEGLAB 2019, we do not recommend using hierarchical clustering. Often simple clustering can achieve similar or better results.
Preclustering details are stored in the STUDY.cluster(2).preclust sub-structure (not shown above but detailed below). For instance, in this case, the cluster.preclust sub-structure may contain the PCA-reduced mean activity spectra (in each of the two conditions) for all 15 components in the cluster.
The cluster.preclust sub-structure contains several fields, for example:
>> STUDY.cluster(2).preclust
ans =
preclustdata: [15x10 double]
preclustparams: { {1x9 cell} }
preclustcomps: {1x4 cell}
The preclustparams field holds an array of cell arrays. Each cell array contains a string that indicates what component measures were used in the clustering (e.g., component spectra (spec), component ersps (ersp), etc…), as well as parameters relevant to the measure. In this example there is only one cell array, since only one measure (the power spectrum) was used in the clustering.
For example:
>> STUDY.cluster(1).preclust.preclustparams
ans =
'spec' 'npca' [10] 'norm' [1] 'weight' [1] 'freqrange' [3 25]
The data measures used in the clustering were the component spectra in a given frequency range (‘’ ‘freqrange’ [3 25]), the spectra were reduced to 10 principal dimensions ( ‘npca’ [10]), normalized ( ‘norm’ [1]), and each given a weight of 1 ( ‘weight’ [1]’). When more than one method is used for clustering, then preclustparams will contain several cell arrays. The preclust.preclustdata field contains the data given to the clustering algorithm (Kmeans). The data size width is the number of ICA components (15) by the number of retained principal components of the spectra (10) shown above. To prevent redundancy, only the measure values of the 15 components in the cluster were left in the data. The other components’ measure data was retained in the other clusters.
The preclust.preclustcomps field is a cell array of size (nsubjects x nsessions) in which each cell holds the components clustered (i.e., all the components of the parent cluster).
Understanding the .sets, .comps substructures for STUDY clusters
In this part, clust will indicate the current cluster of interest. vSTUDY.cluster(clust).sets* and STUDY.cluster(clust).comps fields contain the list of component included in a given cluster. STUDY.cluster(clust).sets is a [datasets_with_same_ica x ncomps] matrix giving the index of the corresponding dataset in STUDY.datasetinfo and corresponds to the components listed in STUDY.cluster(clust).comps. STUDY.cluster(clust).sets and STUDY.cluster(clust).comps have the same number of columns. However, STUDY.cluster(clust).sets may have several rows if some datasets (from the same subject) have the same ICA decomposition - an example is given below of a cluster when each component is contained in two datasets (2 rows for the .sets field) containing identical ICA decompositions.
>> STUDY.cluster(clust)
ans =
name: 'Cls 3'
sets: [2x13 double]
comps: [23 5 13 47 38 3 50 5 12 4 11 3 5]
parent: {'Parentcluster 1'}
If, for some reasons, the STUDY.cluster(clust).sets in not homogeneous – some subjects have several datasets with the same decompositions and other subjects have a different number of datasets with the same decompositions, NaN are inserted for the missing datasets. However, the presence of these missing datasets may break some analysis (warning messages are displayed when relevant).
STUDY data files
When pre-computing measures for a specific STUDY design, some files are saved on disk. These files have names such as
S01.daterp % ERP data for data channels
S01.icaerp % ERP data for ICA components
S01.datspec % Spetrum data for data channels
S01.icaspec % Spetrum data for ICA components
S01.dattimef % Single-trial time-frequency data for data channels
S01.icatimef % Single-trial time-frequency data for ICA components
S01.daterpim % ERPIMAGE data for data channels
S01.icaerpim % ERPIMAGE data for ICA components
S01.icatopo % ICA component topographies
S01 indicate that these files are for subject 1. The name of the file is based on the naming convention in your STUDY. If the first subject is named ‘xx01’ then the file name will start with ‘xx01’. This is also why subjects should not simply be numbers (1, 2, 3, etc…) as most operating systems will not allow saving files that start with a number.
Note that the file naming convention for versions of EEGLAB older than 2019 (EEGLAB 12, 13 and 14) was slightly different, and that the files needed to be recomputed for each STUDY design (which is not the case for EEGLAB 2019 and later versions). Also in old versions of EEGLAB, there were two additional files xxxx.datersp and xxxx.datitc that contained average time-frequency decompositions - since all files now contain single-trial data, these files have been removed.
The file structure is similar for all file types listed below.
>> fileContent = load('-mat', 'S01.daterp');
>> fileContent
ans =
chan1: [750×784 single]
chan2: [750×784 single]
chan3: [750×784 single]
chan4: [750×784 single]
chan5: [750×784 single]
...
chan70: [750×784 single]
chan71: [750×784 single]
labels: {1×71 cell}
times: [1×750 double]
datatype: 'ERP'
parameters: {'rmcomps' {1×3 cell} 'interp' [1×71 struct]}
datafiles: {'/data/data/STUDIES/STERN/S01/Memorize.set' '/data/data/STUDIES/STERN/S01/Ignore.set' '/data/data/STUDIES/STERN/S01/Probe.set'}
trialinfo: [1×784 struct]
The fields chanxx represent ERP data for these channels. For ICA components, the prefix is comp instead of chan. Each channel data will contain an array for time x trials. Below a description of the additional fields:
- labels: This is a cell array of channel labels { ‘Cz’ ‘Pz’ … }. This field is only present for data channels and is not present for ICA components.
- datatype: This field contains the type of data saved in the file. More details are provided below.
- parameters: The parameters used to compute each measure are also stored in the file, for example, the frequency range of the component spectra. Measure files are standard MATLAB files that may be read and processed using standard MATLAB commands. The variable names they contain should be self-explanatory.
- datafile: the list of files used to compute this file.
- trialinfo: information about each data trial. This is similar to the list of information in the field ‘trialinfo’ of STUDY.dataset (however it also includes information about condition, group and session which is stored separately in the STUDY.dataset structure).
The field datatype can take several values:
- ERP: ERP data
- SPECTRUM: SPECTRUM data (legacy)
- TIMEF: time-frequency data
- ERPIMAGE: ERPIMAGE data
Note that for ERPIMAGE data, the comp and chan fields may contain a string of character. If this is the case, the string is executed to load data. This avoids storing the single-trial data multiple times if this is not necessary.